
Seedance 2.0 आ गया है
इन्फ्रास्ट्रक्चर
AI वीडियो और इमेज जेनरेशन के लिए
Higgsfield AI का तेज़, सस्ता विकल्प — सभी शीर्ष मॉडल, एक API।
इन कंपनियों के टीम सदस्यों का भरोसा
// 001: VIDEO_AND_IMAGE_API
हर मॉडल।
एक endpoint।
एक API से कोई भी वीडियो या इमेज मॉडल कॉल करें — एक ही रिक्वेस्ट फॉर्मेट, async जॉब्स, webhooks।

Video1080p · 16:9
Seedance 2.0
सिनेमाई वीडियो
इसके ज़रिए बना Hypereal API · मुफ़्त शुरू करें · Seedance 2.0
API Key पाएं




// 003: REAL_OUTPUT
एक prompt से
तैयार आउटपुट तक।
शीर्ष मॉडल और तैयार काम — Seedance, Kling, Nano Banana, GPT Image 2 और भी। हर टाइल एक API का असली आउटपुट है।







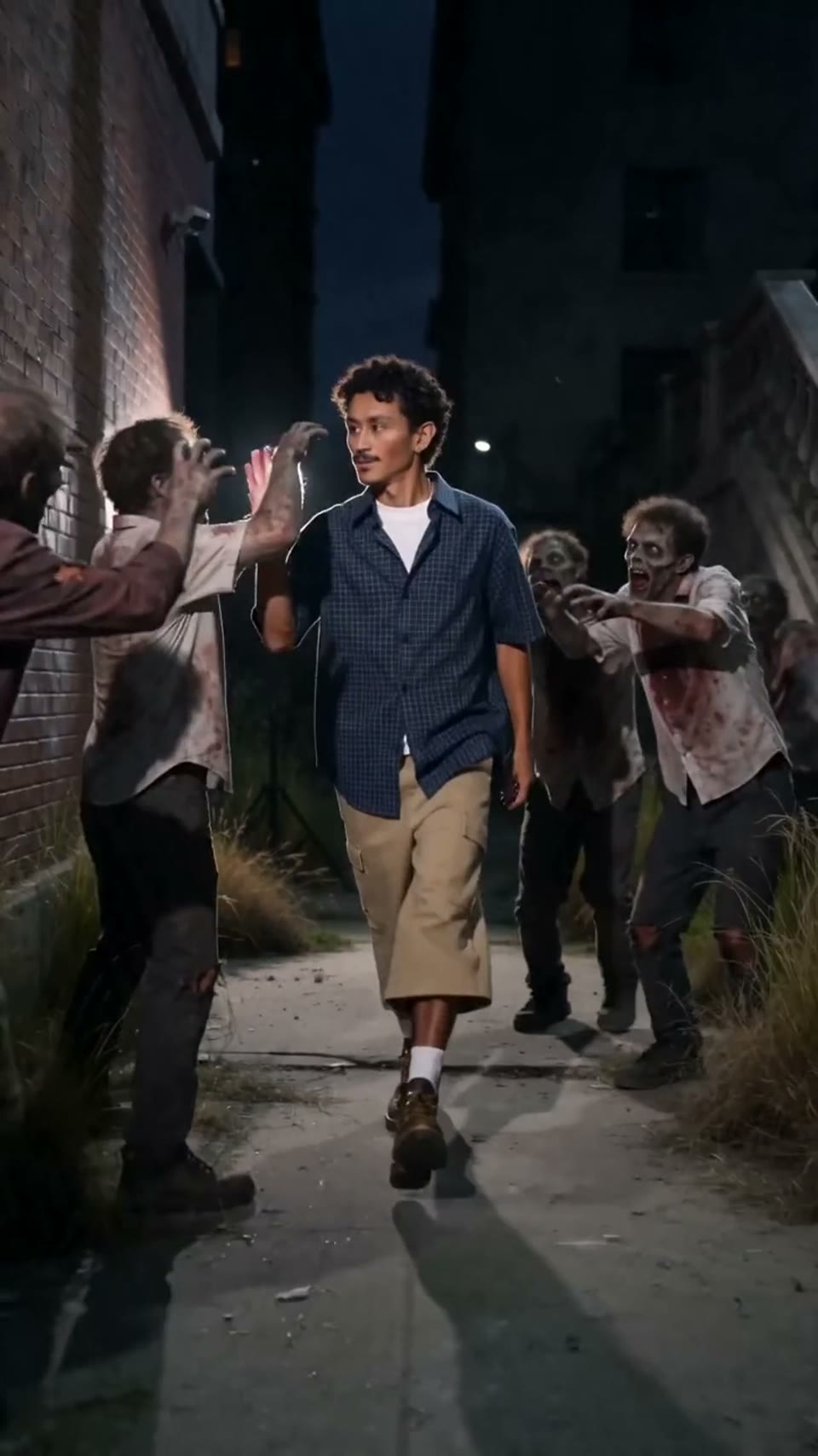




























// 004: ONE_API
एक key।
हर मॉडल।
एक स्ट्रिंग बदलकर मॉडल बदलें। वीडियो और इमेज दोनों के लिए एक ही कॉल फॉर्मेट, async जॉब्स और webhooks।
generate.ts
import { Hypereal } from '@hypereal/sdk';
const hypereal = new Hypereal({ apiKey: process.env.HYPEREAL_KEY });
// Video — Seedance, Kling, Veo, WAN...
const video = await hypereal.video.create({
model: 'seedance-2.0',
prompt: 'Neon city flythrough, cinematic, slow dolly',
aspect_ratio: '16:9',
});
// Image — GPT Image 2, Nano Banana, FLUX...
const image = await hypereal.images.generate({
model: 'gpt-image-2',
prompt: 'Studio product photo of a glass perfume bottle',
});// 005: MODELS_AVAILABLE
Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4
// start_generating