
Seedance 2.0 ist da
Infrastruktur für
KI-Video- und Bildgenerierung
Die schnellere, günstigere Alternative zu Higgsfield AI — alle Top-Modelle, eine API.
Vertraut von Teammitgliedern von
// 001: VIDEO_AND_IMAGE_API
Jedes Modell.
Ein Endpoint.
Rufe jedes Video- oder Bildmodell über eine API auf — gleiche Anfragestruktur, asynchrone Jobs, Webhooks.

Video1080p · 16:9
Seedance 2.0
Kinematografisches Video
Generiert über die Hypereal API · Kostenlos starten · Seedance 2.0
API-Schlüssel holen




// 003: REAL_OUTPUT
Vom Prompt
zum fertigen Ergebnis.
Flaggschiff-Modelle und fertige Arbeiten — Seedance, Kling, Nano Banana, GPT Image 2 und mehr. Jede Kachel ist echter Output aus einer API.







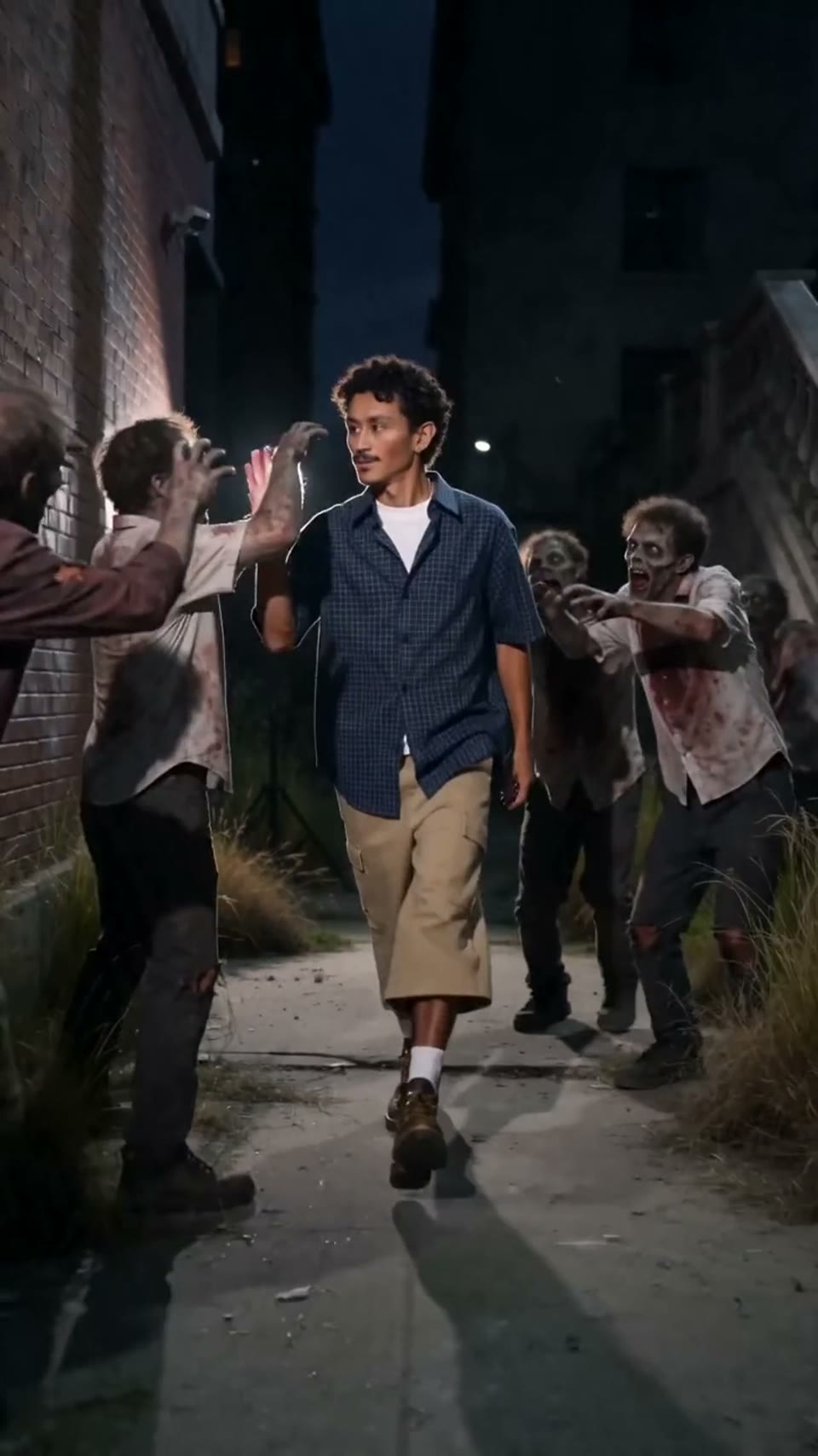




























// 004: ONE_API
Ein Schlüssel.
Jedes Modell.
Modelle wechseln durch Ändern eines einzigen Strings. Gleiche Aufrufstruktur für Video und Bild, async Jobs und Webhooks.
generate.ts
import { Hypereal } from '@hypereal/sdk';
const hypereal = new Hypereal({ apiKey: process.env.HYPEREAL_KEY });
// Video — Seedance, Kling, Veo, WAN...
const video = await hypereal.video.create({
model: 'seedance-2.0',
prompt: 'Neon city flythrough, cinematic, slow dolly',
aspect_ratio: '16:9',
});
// Image — GPT Image 2, Nano Banana, FLUX...
const image = await hypereal.images.generate({
model: 'gpt-image-2',
prompt: 'Studio product photo of a glass perfume bottle',
});// 005: MODELS_AVAILABLE
Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4
// start_generating