
Seedance 2.0 is here
Infra forAI Video & Image Gen
The faster, cheaper Higgsfield AI alternative — every top model, one API.
Trusted by Team Members of
// 001: VIDEO_AND_IMAGE_API
Every model.
One endpoint.
Call any video or image model through one API — same request shape, async jobs, webhooks.

Video1080p · 16:9
Seedance 2.0
Cinematic video
Generated through the Hypereal API · Start free · Seedance 2.0
Get API Key




// 003: REAL_OUTPUT
From a prompt
to finished output.
Flagship models and finished work — Seedance, Kling, Nano Banana, GPT Image 2 and more. Every tile is real output from one API.








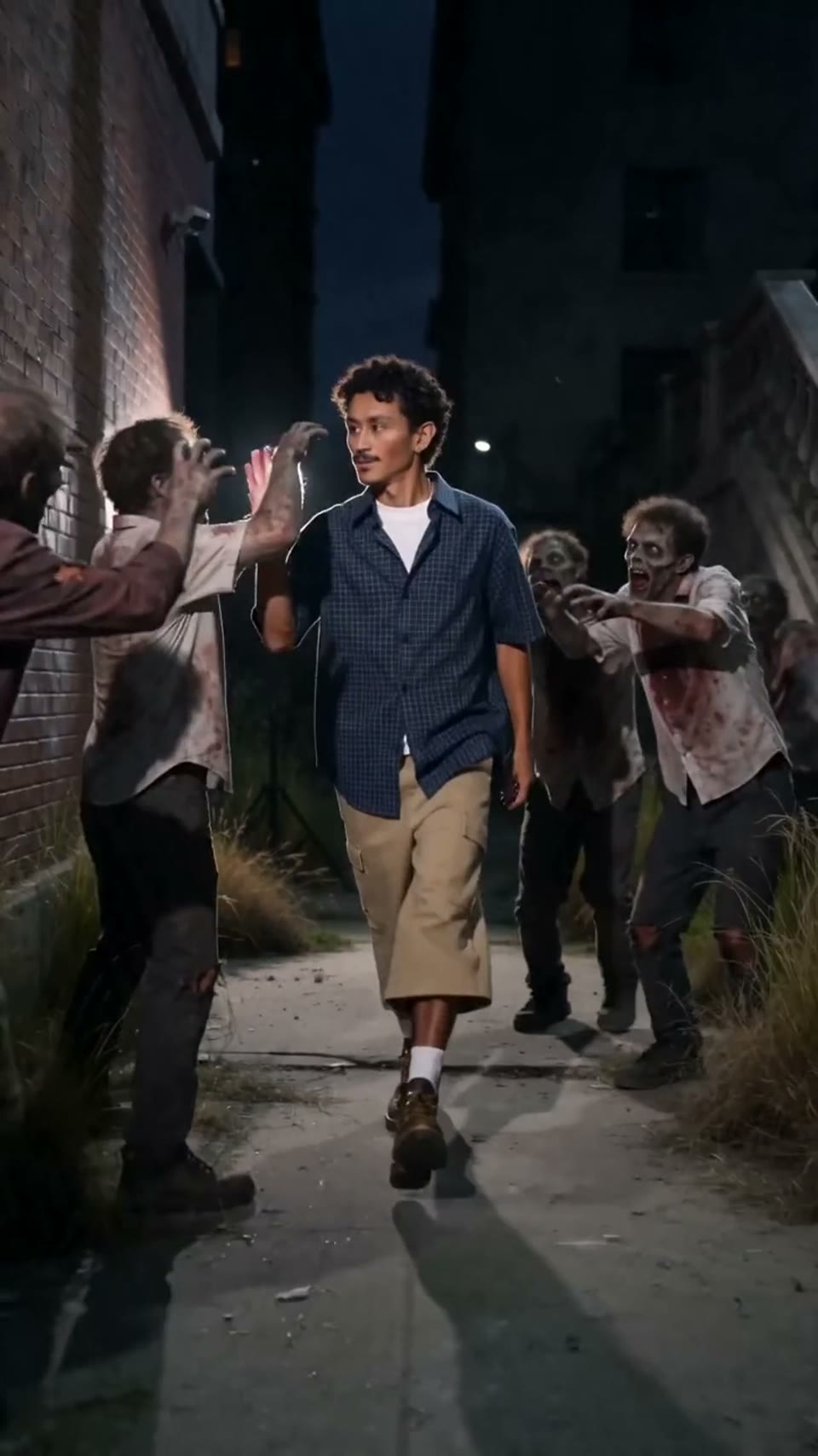




























// 004: ONE_API
One key.
Every model.
Swap models by changing one string. Same call shape for video and image, async jobs, and webhooks.
generate.ts
import { Hypereal } from '@hypereal/sdk';
const hypereal = new Hypereal({ apiKey: process.env.HYPEREAL_KEY });
// Video — Seedance, Kling, Veo, WAN...
const video = await hypereal.video.create({
model: 'seedance-2.0',
prompt: 'Neon city flythrough, cinematic, slow dolly',
aspect_ratio: '16:9',
});
// Image — GPT Image 2, Nano Banana 2 Lite, FLUX...
const image = await hypereal.images.generate({
model: 'nano-banana-2-lite-t2i',
prompt: 'Studio product photo of a glass perfume bottle on marble',
});// 005: MODELS_AVAILABLE
Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano Banana 2 LiteNano BananaFLUX 2Imagen 4Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano Banana 2 LiteNano BananaFLUX 2Imagen 4
// start_generating