
Το Seedance 2.0 είναι εδώ
Υποδομή γιαAI βίντεο και δημιουργία εικόνων
Η ταχύτερη, φθηνότερη εναλλακτική του Higgsfield AI — κάθε κορυφαίο μοντέλο, ένα API.
Έμπιστο από μέλη ομάδων των
// 001: VIDEO_AND_IMAGE_API
Κάθε μοντέλο.
Ένα endpoint.
Καλέστε οποιοδήποτε μοντέλο βίντεο ή εικόνας μέσω ενός API — ίδια δομή αιτήματος, ασύγχρονες εργασίες, webhooks.

Video1080p · 16:9
Seedance 2.0
Κινηματογραφικό βίντεο
Δημιουργήθηκε μέσω Hypereal API · Ξεκινήστε δωρεάν · Seedance 2.0
Αποκτήστε API Key




// 003: REAL_OUTPUT
Από ένα prompt
στο τελικό αποτέλεσμα.
Κορυφαία μοντέλα και ολοκληρωμένες εργασίες — Seedance, Kling, Nano Banana, GPT Image 2 και άλλα. Κάθε πλακίδιο είναι πραγματικό αποτέλεσμα από ένα API.







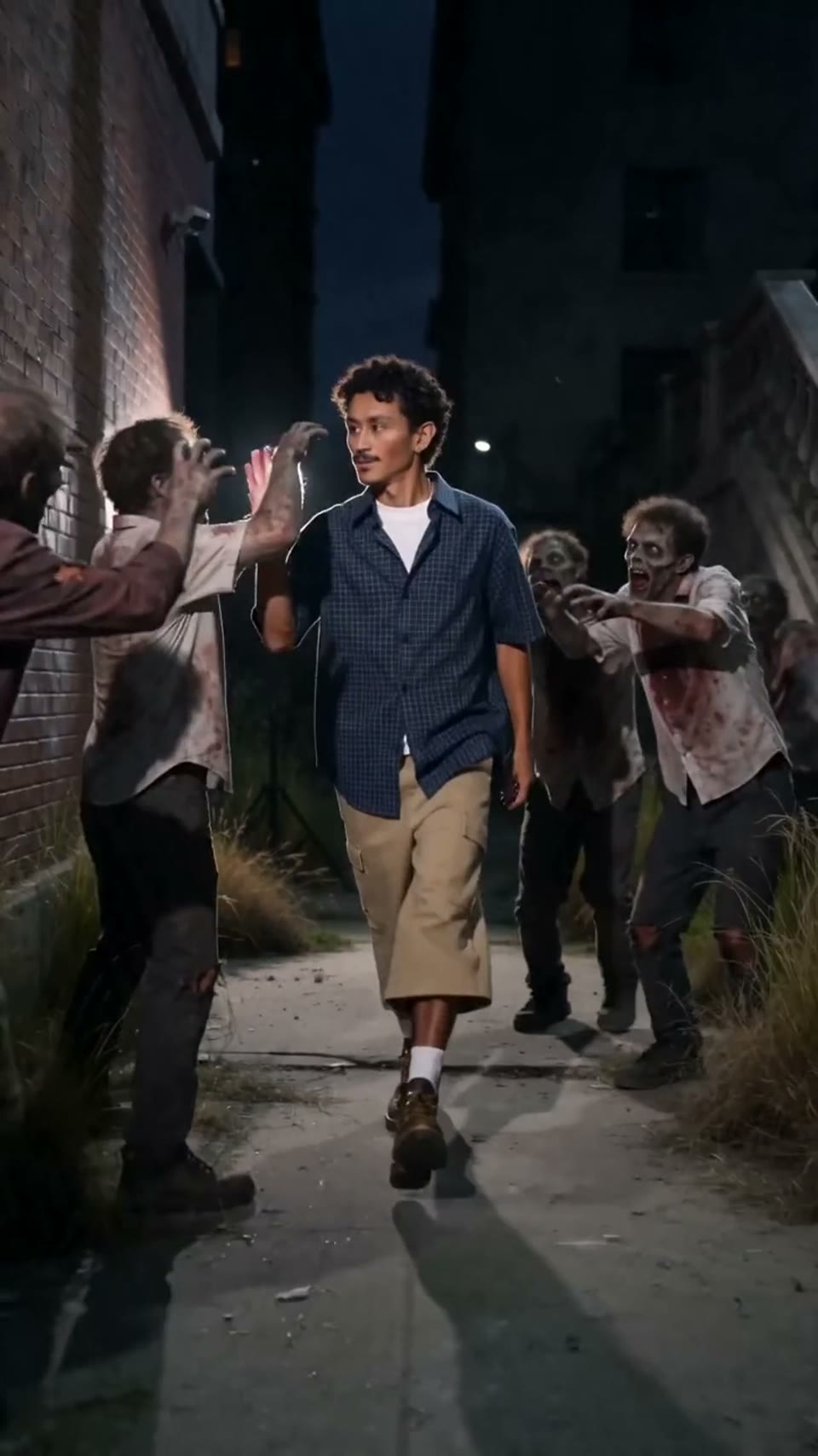




























// 004: ONE_API
Ένα κλειδί.
Κάθε μοντέλο.
Αλλάξτε μοντέλο αλλάζοντας ένα string. Ίδια δομή κλήσης για βίντεο και εικόνες, async εργασίες και webhooks.
generate.ts
import { Hypereal } from '@hypereal/sdk';
const hypereal = new Hypereal({ apiKey: process.env.HYPEREAL_KEY });
// Video — Seedance, Kling, Veo, WAN...
const video = await hypereal.video.create({
model: 'seedance-2.0',
prompt: 'Neon city flythrough, cinematic, slow dolly',
aspect_ratio: '16:9',
});
// Image — GPT Image 2, Nano Banana, FLUX...
const image = await hypereal.images.generate({
model: 'gpt-image-2',
prompt: 'Studio product photo of a glass perfume bottle',
});// 005: MODELS_AVAILABLE
Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4
// start_generating