
Seedance 2.0 już jest
Infrastruktura dla
generowania wideo i obrazów AI
Szybsza i tańsza alternatywa dla Higgsfield AI — wszystkie najlepsze modele, jedno API.
Zaufali członkowie zespołów firm
// 001: VIDEO_AND_IMAGE_API
Każdy model.
Jeden endpoint.
Wywołaj dowolny model wideo lub obrazu przez jedno API — ten sam format żądania, zadania asynchroniczne, webhooks.

Video1080p · 16:9
Seedance 2.0
Wideo kinematograficzne
Wygenerowano przez Hypereal API · Zacznij za darmo · Seedance 2.0
Pobierz klucz API




// 003: REAL_OUTPUT
Od promptu
do gotowego wyniku.
Flagowe modele i gotowe prace — Seedance, Kling, Nano Banana, GPT Image 2 i więcej. Każdy kafelek to rzeczywisty wynik z jednego API.







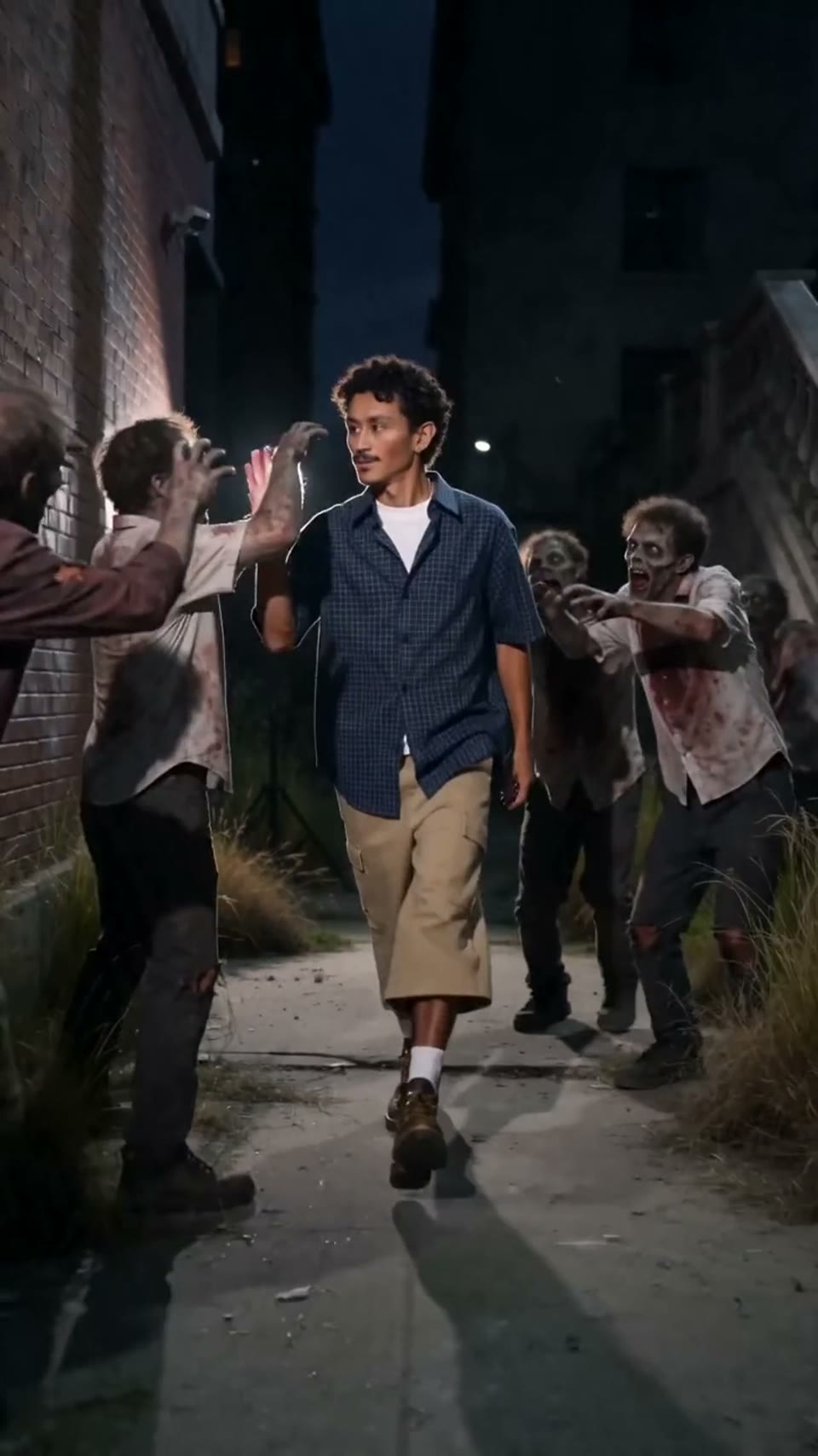




























// 004: ONE_API
Jeden klucz.
Każdy model.
Zmieniaj modele, modyfikując jeden ciąg znaków. Ten sam format wywołania dla wideo i obrazu, zadania asynchroniczne i webhooks.
generate.ts
import { Hypereal } from '@hypereal/sdk';
const hypereal = new Hypereal({ apiKey: process.env.HYPEREAL_KEY });
// Video — Seedance, Kling, Veo, WAN...
const video = await hypereal.video.create({
model: 'seedance-2.0',
prompt: 'Neon city flythrough, cinematic, slow dolly',
aspect_ratio: '16:9',
});
// Image — GPT Image 2, Nano Banana, FLUX...
const image = await hypereal.images.generate({
model: 'gpt-image-2',
prompt: 'Studio product photo of a glass perfume bottle',
});// 005: MODELS_AVAILABLE
Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4
// start_generating