
Seedance 2.0 er her
Infrastruktur tilAI video og billedgenerering
Det hurtigere, billigere alternativ til Higgsfield AI — alle topmodeller, ét API.
Betroet af teammedlemmer hos
// 001: VIDEO_AND_IMAGE_API
Alle modeller.
Ét endpoint.
Kald en hvilken som helst video- eller billedmodel via ét API — samme anmodningsformat, asynkrone jobs, webhooks.

Video1080p · 16:9
Seedance 2.0
Cinematisk video
Genereret via Hypereal API · Start gratis · Seedance 2.0
Få API-nøgle




// 003: REAL_OUTPUT
Fra et prompt
til færdigt output.
Flagskibsmodeller og færdigt arbejde — Seedance, Kling, Nano Banana, GPT Image 2 og mere. Hvert felt er reelt output fra ét API.







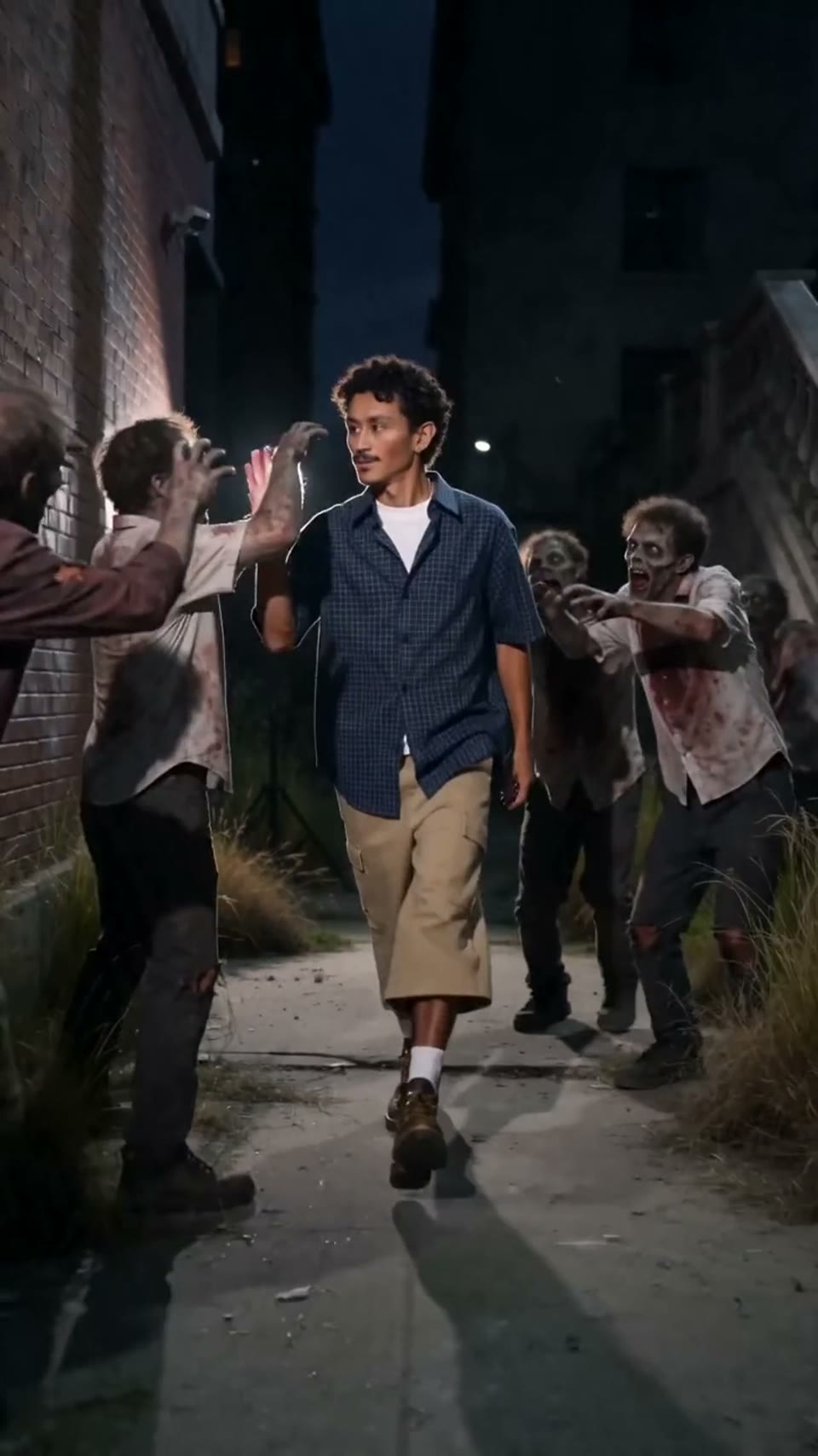




























// 004: ONE_API
Én nøgle.
Alle modeller.
Skift modeller ved at ændre én streng. Samme kaldformat til video og billeder, asynkrone jobs og webhooks.
generate.ts
import { Hypereal } from '@hypereal/sdk';
const hypereal = new Hypereal({ apiKey: process.env.HYPEREAL_KEY });
// Video — Seedance, Kling, Veo, WAN...
const video = await hypereal.video.create({
model: 'seedance-2.0',
prompt: 'Neon city flythrough, cinematic, slow dolly',
aspect_ratio: '16:9',
});
// Image — GPT Image 2, Nano Banana, FLUX...
const image = await hypereal.images.generate({
model: 'gpt-image-2',
prompt: 'Studio product photo of a glass perfume bottle',
});// 005: MODELS_AVAILABLE
Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4
// start_generating