
深受以下公司团队成员信赖
// 001: VIDEO_AND_IMAGE_API
每个模型。
一个端点。
通过单一 API 调用任意视频或图像模型——相同的请求格式、异步任务、Webhook。

Video1080p · 16:9
Seedance 2.0
电影级视频
通过生成: Hypereal API · 免费开始 · Seedance 2.0
获取 API 密钥




// 003: REAL_OUTPUT
从一个 prompt
到完成的成品。
旗舰模型与完整作品——Seedance、Kling、Nano Banana、GPT Image 2 及更多。每个方块都是来自单一 API 的真实输出。








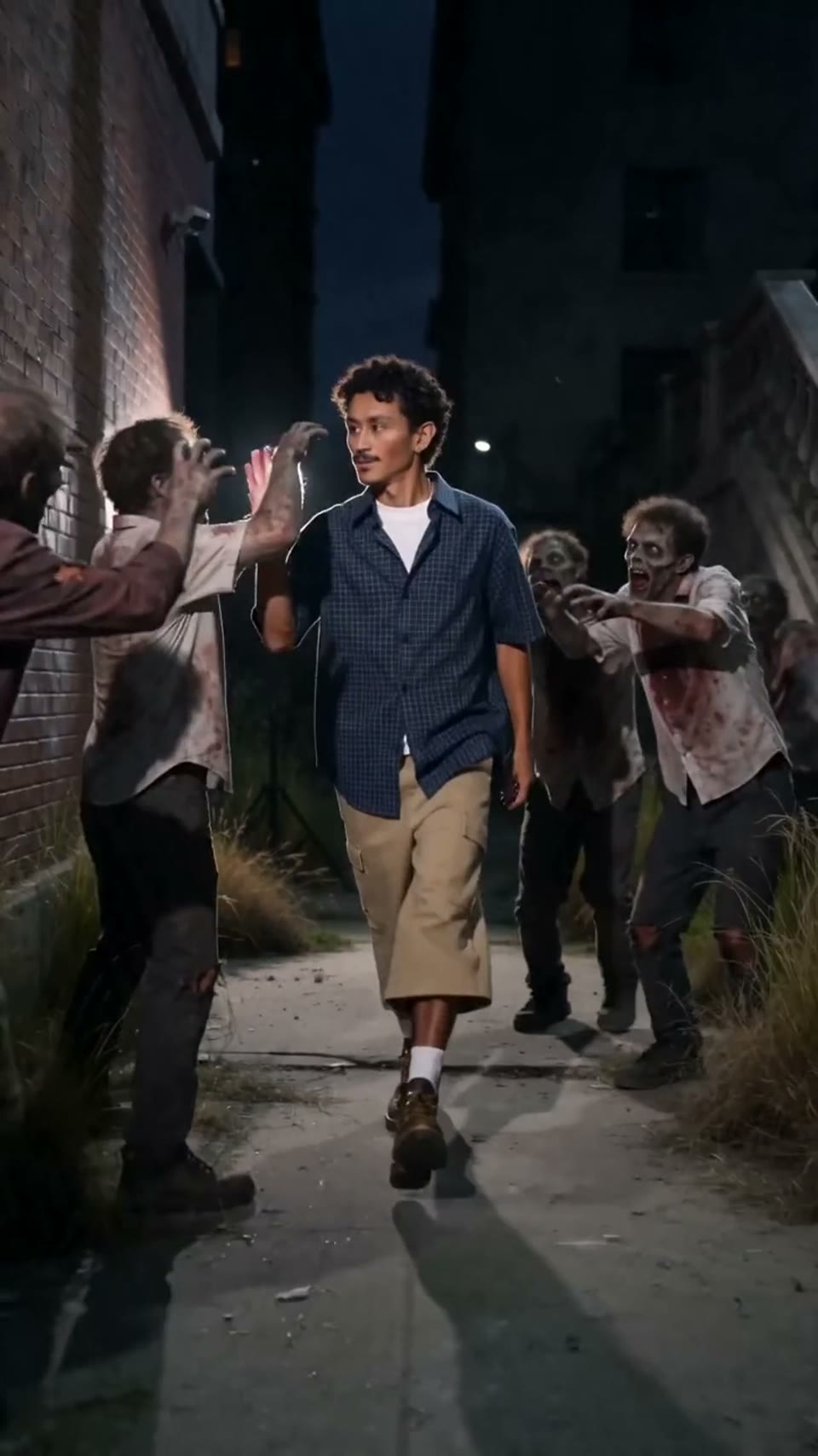




























// 004: ONE_API
generate.ts
import { Hypereal } from '@hypereal/sdk';
const hypereal = new Hypereal({ apiKey: process.env.HYPEREAL_KEY });
// Video — Seedance, Kling, Veo, WAN...
const video = await hypereal.video.create({
model: 'seedance-2.0',
prompt: 'Neon city flythrough, cinematic, slow dolly',
aspect_ratio: '16:9',
});
// Image — GPT Image 2, Nano Banana 2 Lite, FLUX...
const image = await hypereal.images.generate({
model: 'nano-banana-2-lite-t2i',
prompt: 'Studio product photo of a glass perfume bottle on marble',
});// 005: MODELS_AVAILABLE
Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano Banana 2 LiteNano BananaFLUX 2Imagen 4Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano Banana 2 LiteNano BananaFLUX 2Imagen 4