
Seedance 2.0 здесь
Инфраструктура для
AI-генерации видео и изображений
Более быстрая и дешёвая альтернатива Higgsfield AI — все топ-модели, один API.
Нам доверяют члены команд
// 001: VIDEO_AND_IMAGE_API
Любая модель.
Один endpoint.
Вызывайте любую видео- или image-модель через один API — единый формат запроса, асинхронные задачи, вебхуки.

Video1080p · 16:9
Seedance 2.0
Кинематографичное видео
Сгенеровано через Hypereal API · Начать бесплатно · Seedance 2.0
Получить API-ключ




// 003: REAL_OUTPUT
От промпта
до готового результата.
Топ-модели и готовые работы — Seedance, Kling, Nano Banana, GPT Image 2 и другие. Каждый тайл — реальный вывод одного API.







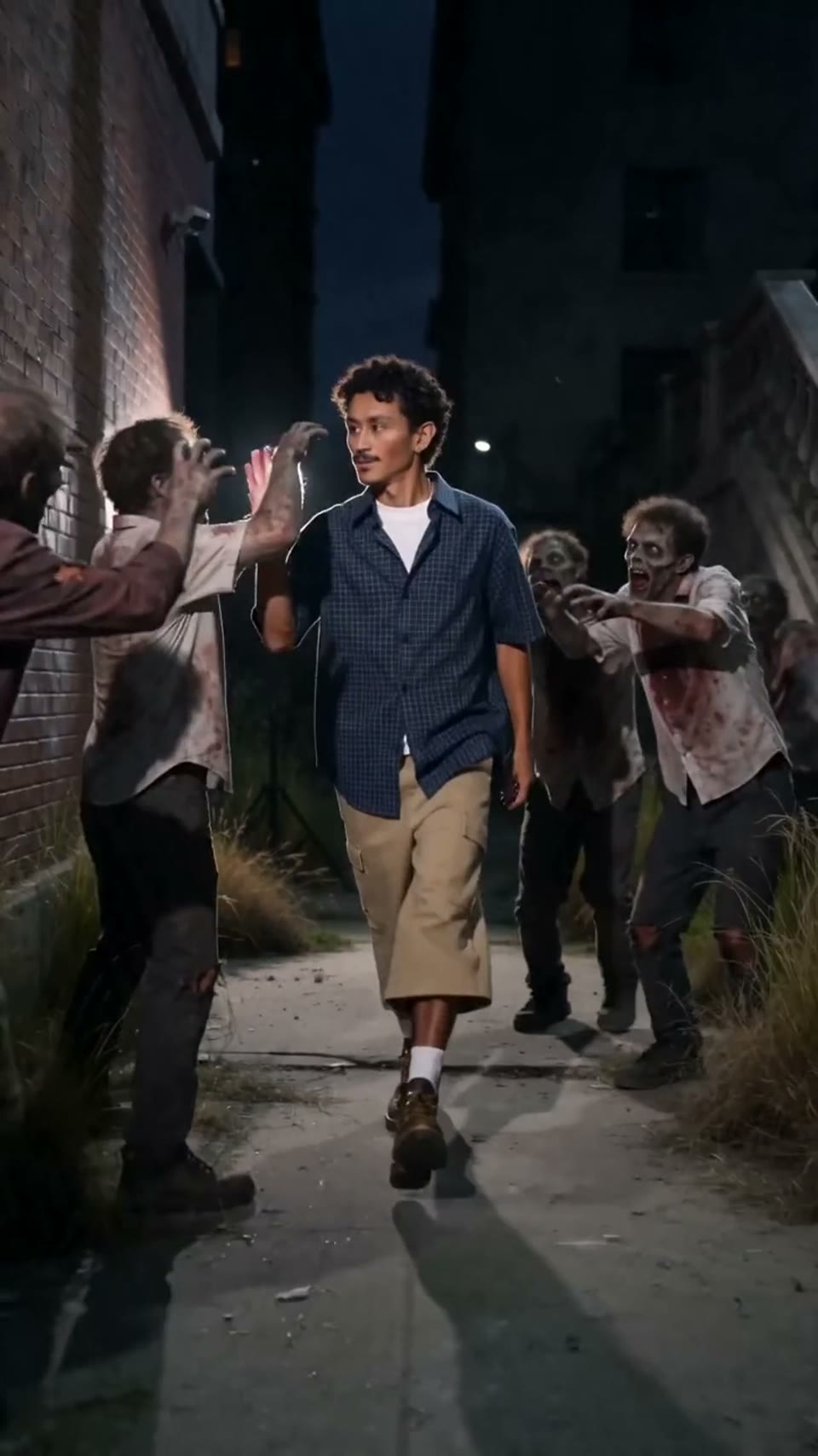




























// 004: ONE_API
Один ключ.
Любая модель.
Меняй модели, изменяя одну строку. Единый формат вызова для видео и изображений, асинхронные задачи и вебхуки.
generate.ts
import { Hypereal } from '@hypereal/sdk';
const hypereal = new Hypereal({ apiKey: process.env.HYPEREAL_KEY });
// Video — Seedance, Kling, Veo, WAN...
const video = await hypereal.video.create({
model: 'seedance-2.0',
prompt: 'Neon city flythrough, cinematic, slow dolly',
aspect_ratio: '16:9',
});
// Image — GPT Image 2, Nano Banana, FLUX...
const image = await hypereal.images.generate({
model: 'gpt-image-2',
prompt: 'Studio product photo of a glass perfume bottle',
});// 005: MODELS_AVAILABLE
Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4
// start_generating