
次の企業のチームメンバーに信頼されています
// 001: VIDEO_AND_IMAGE_API
全モデル対応。
ひとつのエンドポイント。
動画・画像モデルをひとつのAPIから呼び出す——同一リクエスト形式、非同期ジョブ、Webhook対応。

Video1080p · 16:9
Seedance 2.0
シネマティック動画
生成元: Hypereal API · 無料で始める · Seedance 2.0
APIキーを取得




// 003: REAL_OUTPUT
プロンプトから
完成品まで。
主力モデルの実際の出力——Seedance、Kling、Nano Banana、GPT Image 2など。全タイルがひとつのAPIからの本物の生成結果。








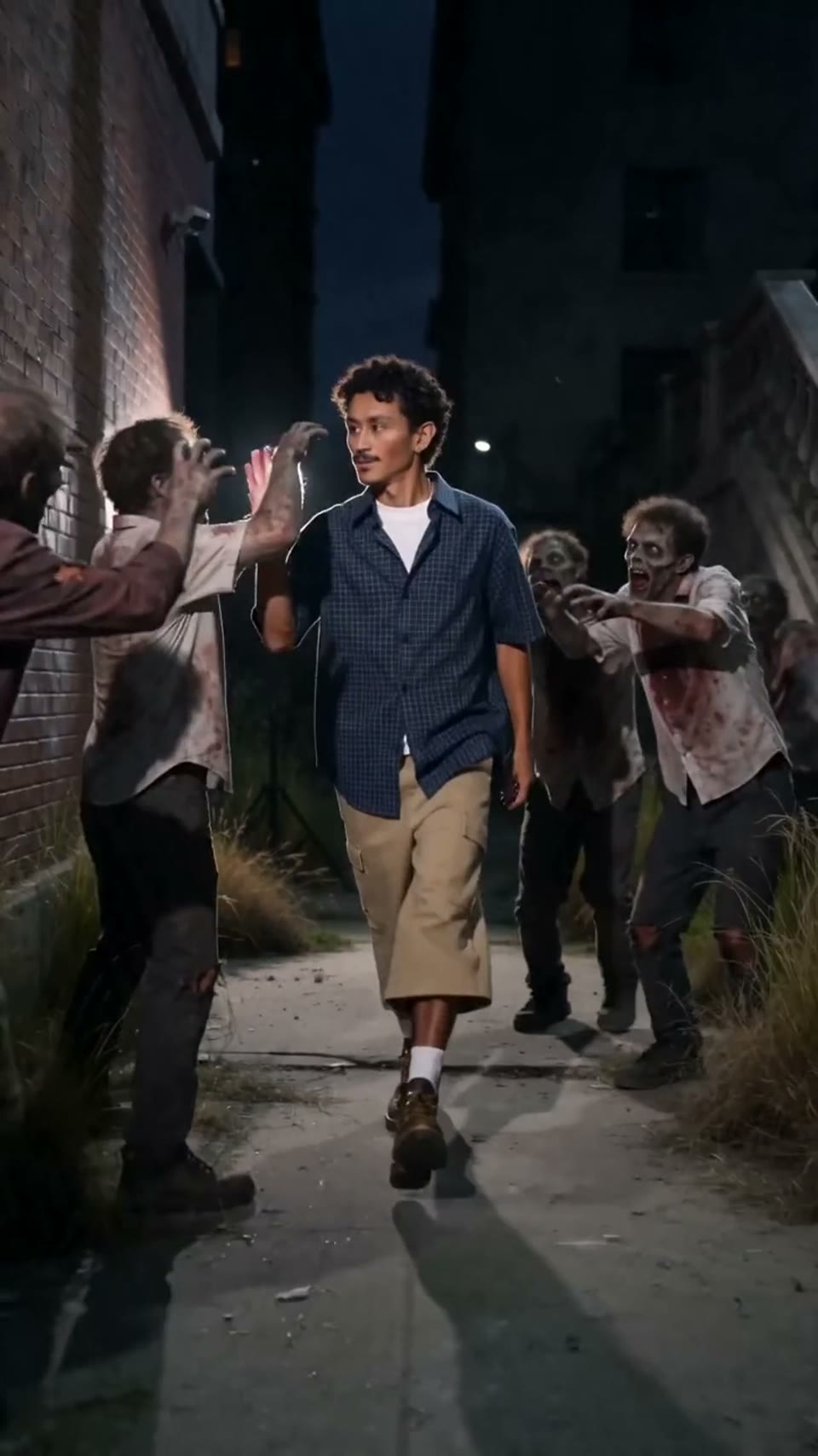




























// 004: ONE_API
generate.ts
import { Hypereal } from '@hypereal/sdk';
const hypereal = new Hypereal({ apiKey: process.env.HYPEREAL_KEY });
// Video — Seedance, Kling, Veo, WAN...
const video = await hypereal.video.create({
model: 'seedance-2.0',
prompt: 'Neon city flythrough, cinematic, slow dolly',
aspect_ratio: '16:9',
});
// Image — GPT Image 2, Nano Banana 2 Lite, FLUX...
const image = await hypereal.images.generate({
model: 'nano-banana-2-lite-t2i',
prompt: 'Studio product photo of a glass perfume bottle on marble',
});// 005: MODELS_AVAILABLE
Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano Banana 2 LiteNano BananaFLUX 2Imagen 4Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano Banana 2 LiteNano BananaFLUX 2Imagen 4