
Nandito na ang Seedance 2.0
Imprastraktura para saAI Video at Image Gen
Ang mas mabilis, mas murang alternatibo sa Higgsfield AI — bawat nangungunang modelo, isang API.
Pinagkakatiwalaan ng mga Team Member ng
// 001: VIDEO_AND_IMAGE_API
Bawat modelo.
Isang endpoint.
I-call ang anumang video o image model sa isang API — parehong request shape, async jobs, webhooks.

Video1080p · 16:9
Seedance 2.0
Cinematic na video
Ginawa sa pamamagitan ng Hypereal API · Magsimula nang libre · Seedance 2.0
Kumuha ng API Key




// 003: REAL_OUTPUT
Mula sa prompt
hanggang tapos na output.
Mga flagship na modelo at tapos na gawa — Seedance, Kling, Nano Banana, GPT Image 2 at marami pa. Bawat tile ay tunay na output mula sa isang API.







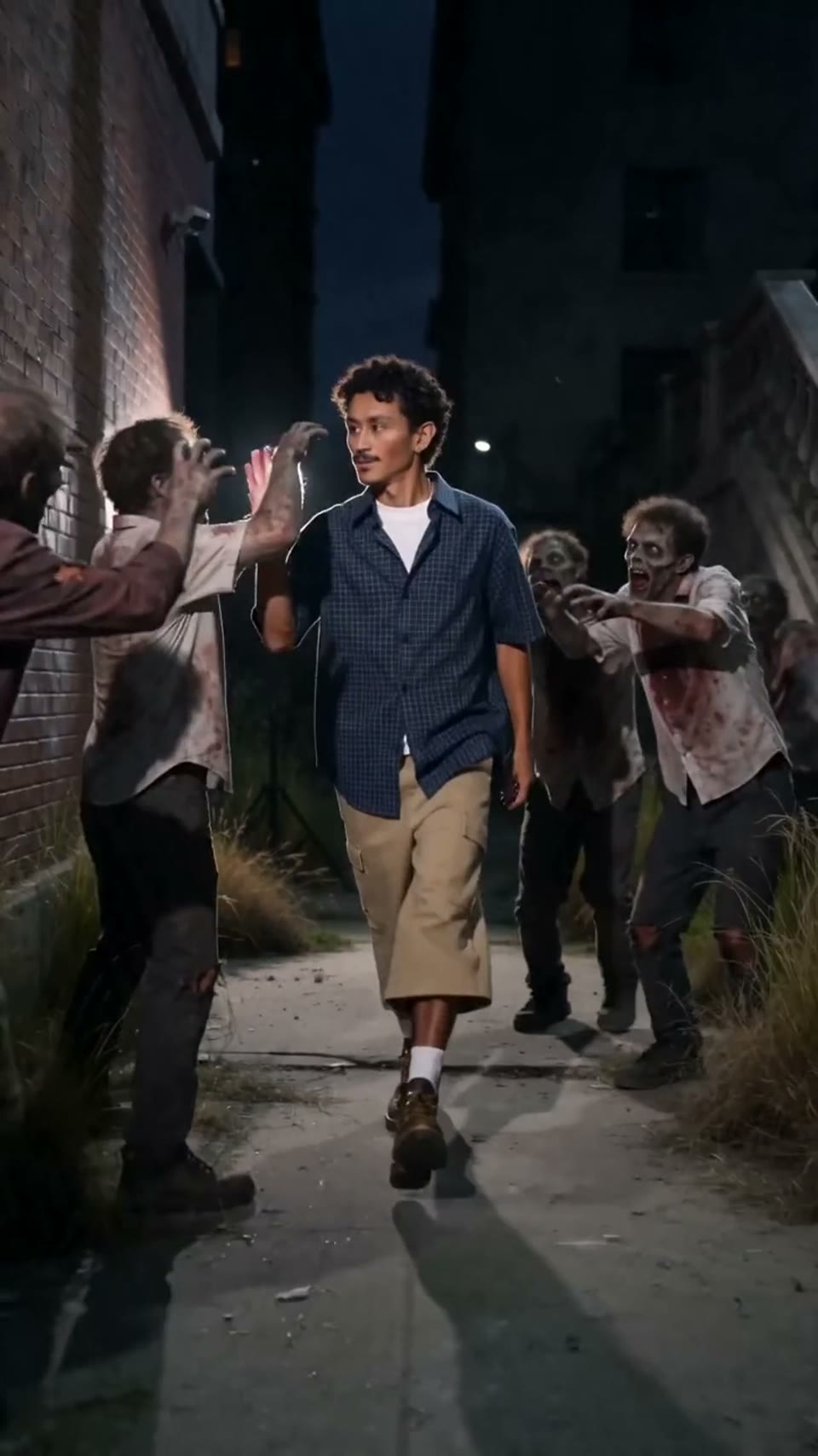




























// 004: ONE_API
Isang key.
Bawat modelo.
Palitan ang mga modelo sa pagbabago ng isang string. Parehong call shape para sa video at image, async jobs, at webhooks.
generate.ts
import { Hypereal } from '@hypereal/sdk';
const hypereal = new Hypereal({ apiKey: process.env.HYPEREAL_KEY });
// Video — Seedance, Kling, Veo, WAN...
const video = await hypereal.video.create({
model: 'seedance-2.0',
prompt: 'Neon city flythrough, cinematic, slow dolly',
aspect_ratio: '16:9',
});
// Image — GPT Image 2, Nano Banana, FLUX...
const image = await hypereal.images.generate({
model: 'gpt-image-2',
prompt: 'Studio product photo of a glass perfume bottle',
});// 005: MODELS_AVAILABLE
Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4
// start_generating