
Seedance 2.0 ir klāt
InfrastruktūraAI video un attēlu ģenerācijai
Ātrāka un lētāka Higgsfield AI alternatīva — visi labākie modeļi, viens API.
Uzticas komandas no
// 001: VIDEO_AND_IMAGE_API
Katrs modelis.
Viens endpoint.
Izsauciet jebkuru video vai attēlu modeli caur vienu API — vienāds pieprasījuma formāts, asinhroni uzdevumi, vebhāki.

Video1080p · 16:9
Seedance 2.0
Kinematogrāfisks video
Izveidots ar Hypereal API · Sāciet bez maksas · Seedance 2.0
Iegūt API atslēgu




// 003: REAL_OUTPUT
No prompta
līdz gatavam rezultātam.
Vadošie modeļi un pabeigtie darbi — Seedance, Kling, Nano Banana, GPT Image 2 un citi. Katra flīze ir īsts viena API rezultāts.







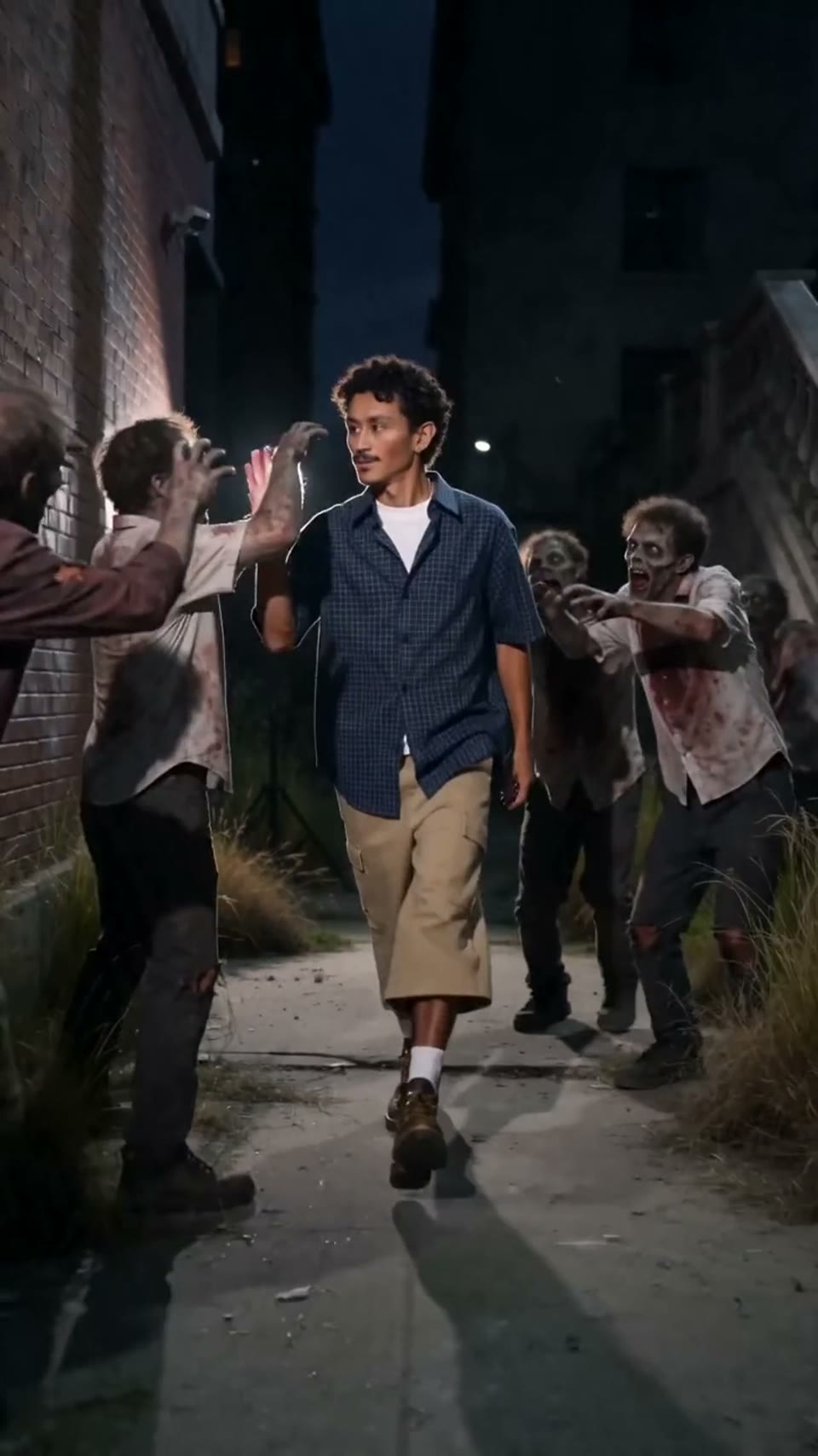




























// 004: ONE_API
Viena atslēga.
Katrs modelis.
Maini modeli, mainot vienu virkni. Vienāds izsaukuma formāts video un attēliem, asinhroni uzdevumi un vebhāki.
generate.ts
import { Hypereal } from '@hypereal/sdk';
const hypereal = new Hypereal({ apiKey: process.env.HYPEREAL_KEY });
// Video — Seedance, Kling, Veo, WAN...
const video = await hypereal.video.create({
model: 'seedance-2.0',
prompt: 'Neon city flythrough, cinematic, slow dolly',
aspect_ratio: '16:9',
});
// Image — GPT Image 2, Nano Banana, FLUX...
const image = await hypereal.images.generate({
model: 'gpt-image-2',
prompt: 'Studio product photo of a glass perfume bottle',
});// 005: MODELS_AVAILABLE
Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4
// start_generating