
Seedance 2.0 a sosit
Infrastructură pentrugenerare video și imagini AI
Alternativa mai rapidă și mai ieftină la Higgsfield AI — toate modelele de top, un singur API.
Folosit cu încredere de membrii echipei de la
// 001: VIDEO_AND_IMAGE_API
Orice model.
Un singur endpoint.
Apelează orice model video sau imagine printr-un singur API — același format de cerere, joburi asincrone, webhookuri.

Video1080p · 16:9
Seedance 2.0
Video cinematografic
Generat prin Hypereal API · Începe gratuit · Seedance 2.0
Obține cheie API




// 003: REAL_OUTPUT
De la un prompt
la rezultat final.
Modele de top și lucrări finalizate — Seedance, Kling, Nano Banana, GPT Image 2 și altele. Fiecare casetă este output real dintr-un singur API.







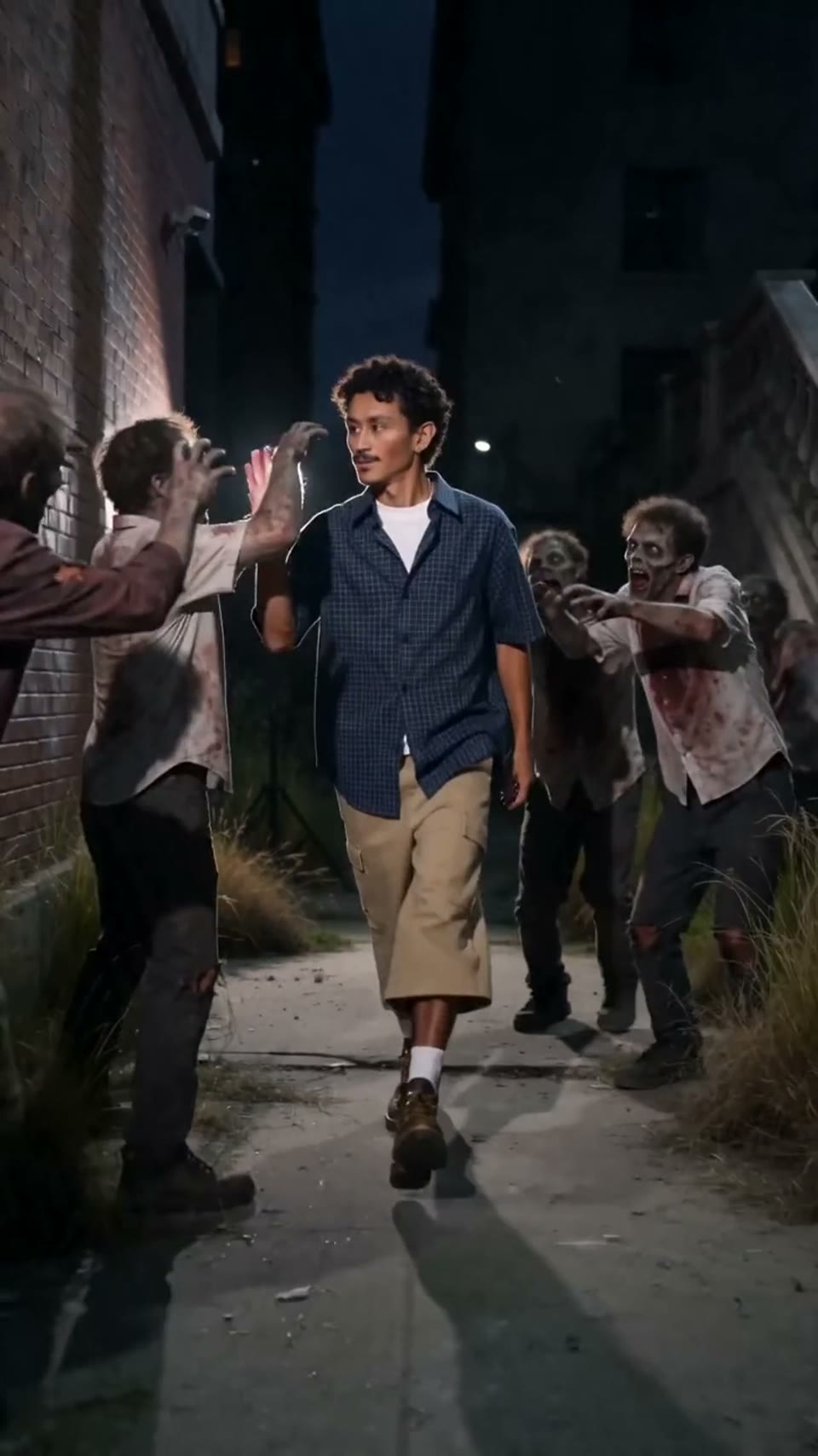




























// 004: ONE_API
O cheie.
Orice model.
Schimbă modelele modificând un singur șir. Același format de apel pentru video și imagini, joburi asincrone și webhookuri.
generate.ts
import { Hypereal } from '@hypereal/sdk';
const hypereal = new Hypereal({ apiKey: process.env.HYPEREAL_KEY });
// Video — Seedance, Kling, Veo, WAN...
const video = await hypereal.video.create({
model: 'seedance-2.0',
prompt: 'Neon city flythrough, cinematic, slow dolly',
aspect_ratio: '16:9',
});
// Image — GPT Image 2, Nano Banana, FLUX...
const image = await hypereal.images.generate({
model: 'gpt-image-2',
prompt: 'Studio product photo of a glass perfume bottle',
});// 005: MODELS_AVAILABLE
Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4
// start_generating