
Seedance 2.0 כאן
תשתית ליצירת וידאו ותמונות עם AI
האלטרנטיבה המהירה והזולה יותר ל-Higgsfield AI — כל המודלים המובילים, API אחד.
באמון על ידי חברי צוות של
// 001: VIDEO_AND_IMAGE_API
כל מודל.
endpoint אחד.
קרא לכל מודל וידאו או תמונה דרך API אחד — אותו פורמט בקשה, משימות אסינכרוניות, webhooks.

Video1080p · 16:9
Seedance 2.0
וידאו קולנועי
נוצר דרך Hypereal API · התחל בחינם · Seedance 2.0
קבל מפתח API




// 003: REAL_OUTPUT
מ-prompt
לתוצר מוגמר.
מודלים מובילים ועבודות גמורות — Seedance, Kling, Nano Banana, GPT Image 2 ועוד. כל כרטיס הוא פלט אמיתי מ-API אחד.







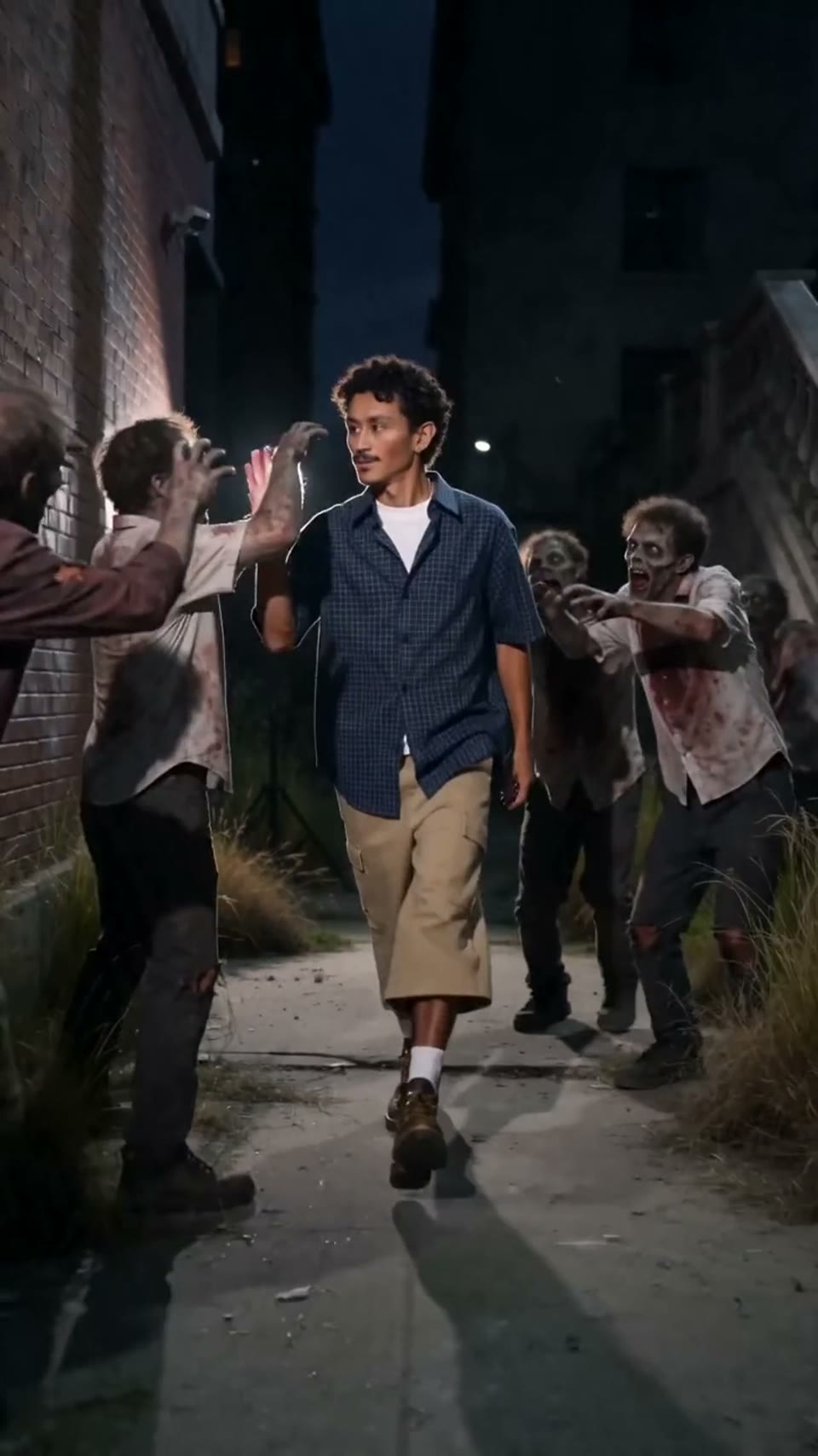




























// 004: ONE_API
מפתח אחד.
כל מודל.
החלף מודלים בשינוי מחרוזת אחת. אותה מבנה קריאה לוידאו ותמונה, משימות אסינכרוניות ו-webhooks.
generate.ts
import { Hypereal } from '@hypereal/sdk';
const hypereal = new Hypereal({ apiKey: process.env.HYPEREAL_KEY });
// Video — Seedance, Kling, Veo, WAN...
const video = await hypereal.video.create({
model: 'seedance-2.0',
prompt: 'Neon city flythrough, cinematic, slow dolly',
aspect_ratio: '16:9',
});
// Image — GPT Image 2, Nano Banana, FLUX...
const image = await hypereal.images.generate({
model: 'gpt-image-2',
prompt: 'Studio product photo of a glass perfume bottle',
});// 005: MODELS_AVAILABLE
Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4
// start_generating