
Seedance 2.0 è arrivato
Infrastruttura per
la generazione video e immagini con IA
L'alternativa più veloce ed economica a Higgsfield AI — ogni modello top, una sola API.
Apprezzato dai membri dei team di
// 001: VIDEO_AND_IMAGE_API
Ogni modello.
Un endpoint.
Chiama qualsiasi modello video o immagine tramite una sola API — stesso formato di richiesta, job asincroni, webhook.

Video1080p · 16:9
Seedance 2.0
Video cinematografico
Generato tramite Hypereal API · Inizia gratis · Seedance 2.0
Ottieni chiave API




// 003: REAL_OUTPUT
Da un prompt
all'output finito.
Modelli di punta e lavori completati — Seedance, Kling, Nano Banana, GPT Image 2 e altro. Ogni tile è output reale da una sola API.







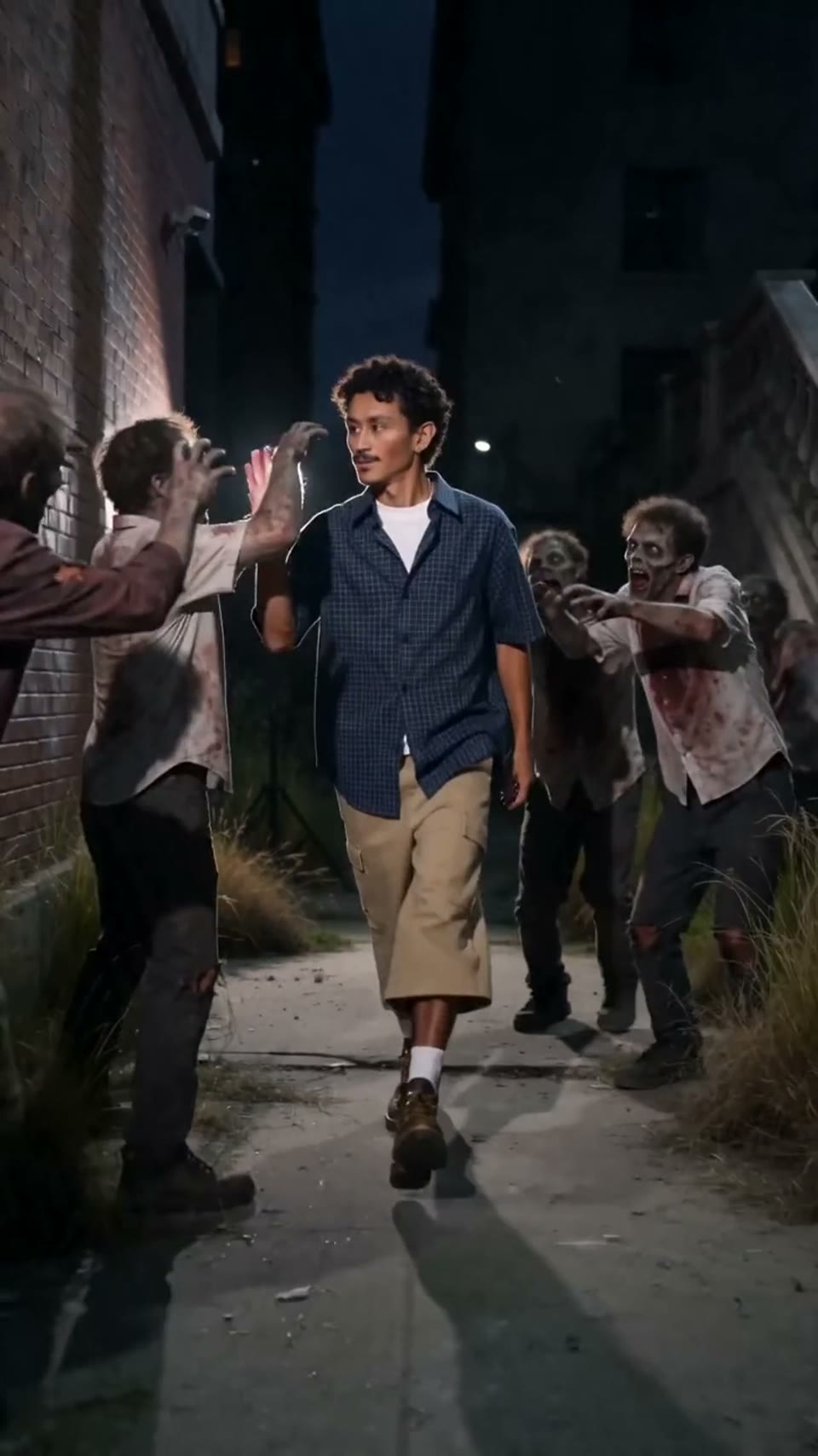




























// 004: ONE_API
Una chiave.
Ogni modello.
Cambia modello modificando una sola stringa. Stesso formato di chiamata per video e immagini, job asincroni e webhook.
generate.ts
import { Hypereal } from '@hypereal/sdk';
const hypereal = new Hypereal({ apiKey: process.env.HYPEREAL_KEY });
// Video — Seedance, Kling, Veo, WAN...
const video = await hypereal.video.create({
model: 'seedance-2.0',
prompt: 'Neon city flythrough, cinematic, slow dolly',
aspect_ratio: '16:9',
});
// Image — GPT Image 2, Nano Banana, FLUX...
const image = await hypereal.images.generate({
model: 'gpt-image-2',
prompt: 'Studio product photo of a glass perfume bottle',
});// 005: MODELS_AVAILABLE
Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4
// start_generating