
Seedance 2.0 je tady
Infrastruktura proAI video a generování obrázků
Rychlejší a levnější alternativa k Higgsfield AI — každý top model, jedno API.
Důvěřují tomu členové týmů z
// 001: VIDEO_AND_IMAGE_API
Každý model.
Jeden endpoint.
Volejte jakýkoli video nebo obrazový model přes jedno API — stejný formát požadavku, async úlohy, webhooky.

Video1080p · 16:9
Seedance 2.0
Kinematografické video
Vygenerováno přes Hypereal API · Začněte zdarma · Seedance 2.0
Získat API klíč




// 003: REAL_OUTPUT
Z promptu
k hotovému výstupu.
Vlajkové modely a hotové práce — Seedance, Kling, Nano Banana, GPT Image 2 a další. Každá dlaždice je reálný výstup z jednoho API.







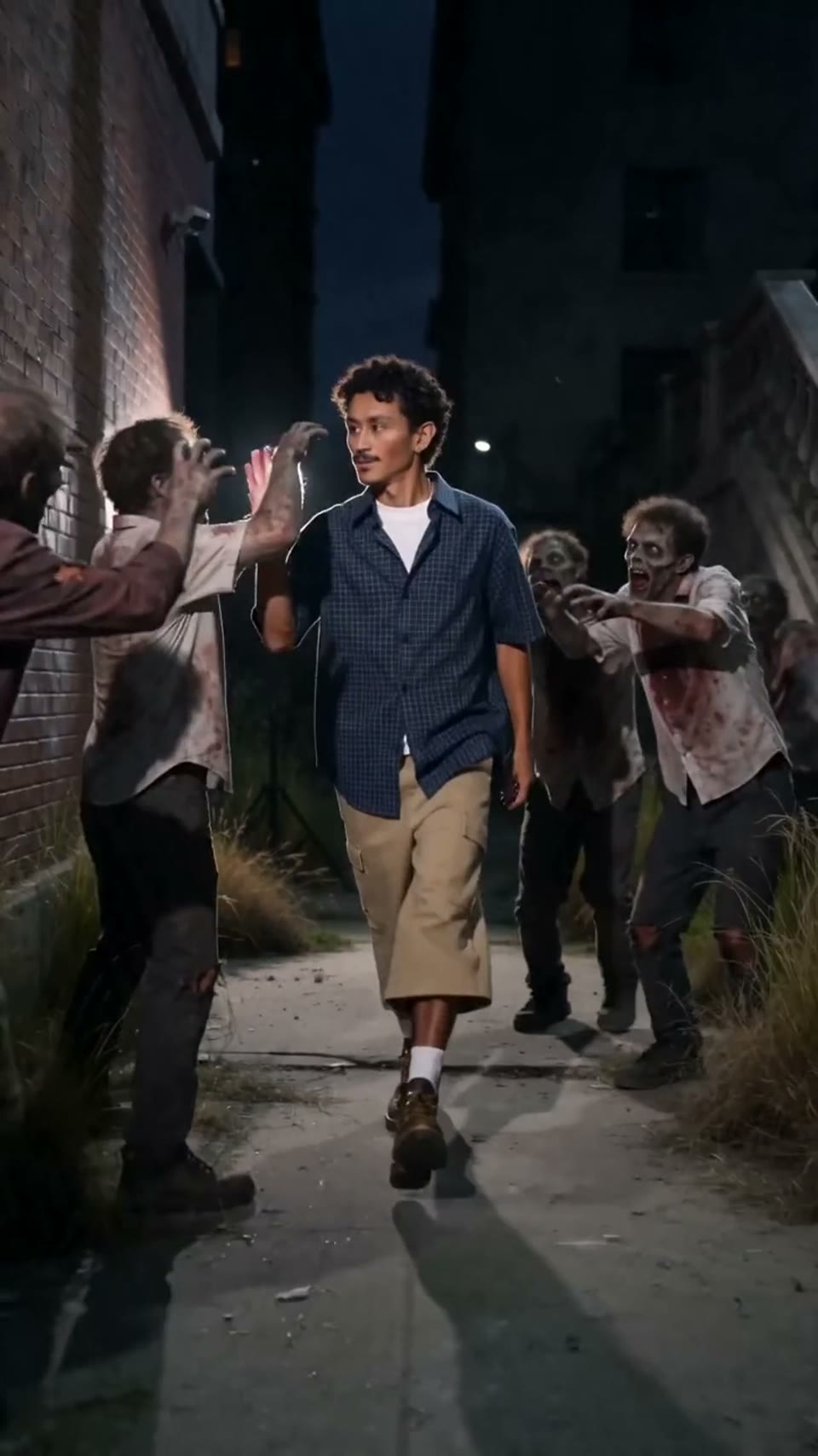




























// 004: ONE_API
Jeden klíč.
Každý model.
Měňte modely změnou jednoho řetězce. Stejný formát volání pro video i obrázky, async úlohy a webhooky.
generate.ts
import { Hypereal } from '@hypereal/sdk';
const hypereal = new Hypereal({ apiKey: process.env.HYPEREAL_KEY });
// Video — Seedance, Kling, Veo, WAN...
const video = await hypereal.video.create({
model: 'seedance-2.0',
prompt: 'Neon city flythrough, cinematic, slow dolly',
aspect_ratio: '16:9',
});
// Image — GPT Image 2, Nano Banana, FLUX...
const image = await hypereal.images.generate({
model: 'gpt-image-2',
prompt: 'Studio product photo of a glass perfume bottle',
});// 005: MODELS_AVAILABLE
Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4
// start_generating