
Seedance 2.0 آ گیا
انفراسٹرکچرAI ویڈیو اور تصویر سازی کے لیے
Higgsfield AI سے تیز اور سستا متبادل — ہر بہترین ماڈل، ایک API۔
ٹیم ممبران کے ذریعے قابل اعتماد
// 001: VIDEO_AND_IMAGE_API
ہر ماڈل۔
ایک endpoint۔
کوئی بھی ویڈیو یا تصویر ماڈل ایک API سے کال کریں — ایک جیسا request format، async jobs، webhooks۔

Video1080p · 16:9
Seedance 2.0
سنیماٹک ویڈیو
تیار کردہ بذریعہ Hypereal API · مفت شروع کریں · Seedance 2.0
API کلید حاصل کریں




// 003: REAL_OUTPUT
prompt سے
مکمل آؤٹ پٹ تک۔
بہترین ماڈل اور مکمل کام — Seedance, Kling, Nano Banana, GPT Image 2 اور مزید۔ ہر tile ایک API کا حقیقی آؤٹ پٹ ہے۔







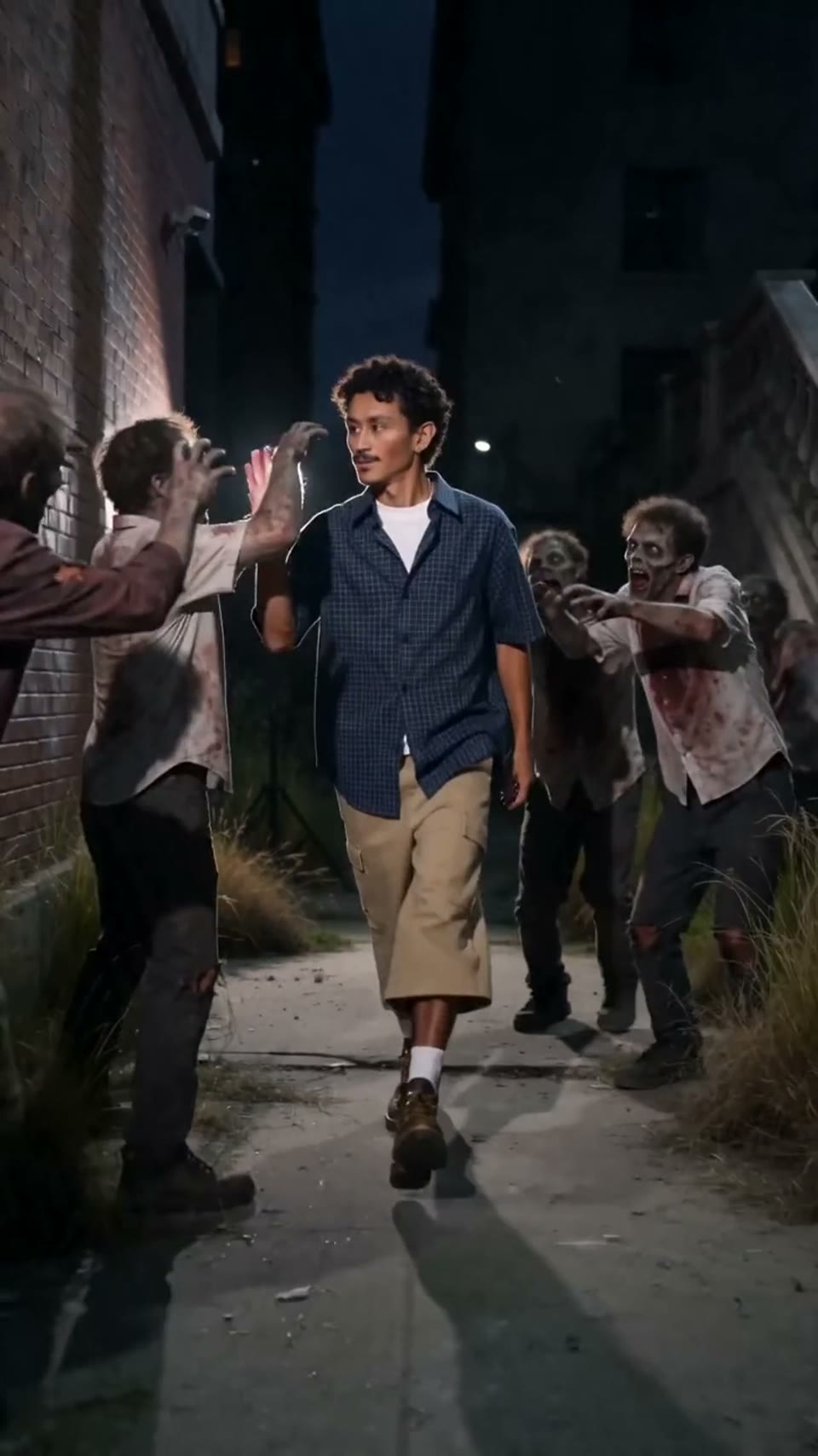




























// 004: ONE_API
ایک کلید۔
ہر ماڈل۔
ایک string بدل کر ماڈل تبدیل کریں۔ ویڈیو اور تصویر دونوں کے لیے ایک جیسا call format، async jobs اور webhooks۔
generate.ts
import { Hypereal } from '@hypereal/sdk';
const hypereal = new Hypereal({ apiKey: process.env.HYPEREAL_KEY });
// Video — Seedance, Kling, Veo, WAN...
const video = await hypereal.video.create({
model: 'seedance-2.0',
prompt: 'Neon city flythrough, cinematic, slow dolly',
aspect_ratio: '16:9',
});
// Image — GPT Image 2, Nano Banana, FLUX...
const image = await hypereal.images.generate({
model: 'gpt-image-2',
prompt: 'Studio product photo of a glass perfume bottle',
});// 005: MODELS_AVAILABLE
Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4Seedance 2.0Kling 3.0Veo 3.1WAN 2.7Hailuo 2.3Sora 2GPT Image 2Nano BananaFLUX 2Imagen 4
// start_generating